Chaque trimestre apporte son lot d’annonces : un nouveau modèle frontier, des benchmarks records, des demos impressionnantes. Et chaque fois, la même question des équipes techniques : qu’est-ce qu’on fait avec ça ?
La fin 2025 a été particulièrement dense. Claude Opus 4.5 d’Anthropic, les nouvelles versions de GPT-5, Gemini Ultra 2, chacun revendique des gains significatifs sur le raisonnement, la fenêtre de contexte, les capacités agentiques. Certains de ces gains sont réels et matériels pour des applications en production. D’autres sont des améliorations sur des benchmarks académiques qui ne se traduisent pas nécessairement en valeur opérationnelle.
Voici un regard sans hype sur ce qui change vraiment.
Ce qui a réellement évolué
La fenêtre de contexte : un changement structurant
La fenêtre de contexte des modèles frontier a franchi des seuils qui changent les architectures possibles. Là où les premiers GPT-4 travaillaient sur 8k tokens (environ 6 000 mots), les modèles actuels opèrent sur des centaines de milliers à plusieurs millions de tokens.
Ce que ça change concrètement :
Le pattern RAG (Retrieval-Augmented Generation), qui consiste à récupérer les passages pertinents d’une base documentaire et les injecter dans le contexte, reste utile pour des raisons de coût et de précision. Mais il n’est plus la seule réponse à “le document est trop long pour le contexte”. Des documents de plusieurs centaines de pages peuvent désormais être traités directement.
Pour les systèmes d’analyse documentaire (contrats, dossiers réglementaires, rapports d’audit), c’est une simplification architecturale significative : moins de chunking, moins de logique de récupération, moins de risque de perdre des informations importantes dans les coutures entre fragments.
Ce que ça ne change pas : le coût d’inférence est proportionnel aux tokens traités. Envoyer 500 000 tokens à chaque appel pour un cas d’usage qui n’en a pas besoin est économiquement absurde. Le RAG reste pertinent pour la maîtrise des coûts sur des bases documentaires larges.
Le raisonnement : des gains réels sur certains types de tâches
Les modèles de la génération actuelle (famille “o” d’OpenAI, Claude avec extended thinking activé, Gemini avec Deep Research) ont des capacités de raisonnement en plusieurs étapes significativement améliorées par rapport à leurs prédécesseurs.
Sur quoi ça se voit vraiment :
- Analyse de problèmes à plusieurs contraintes (optimisation, planification)
- Débogage de code complexe avec traçage de l’état intermédiaire
- Analyse juridique ou réglementaire nécessitant de croiser plusieurs sources
- Génération de code avec architecture cohérente sur des problèmes non triviaux
Là où les benchmarks surestiment les gains : Les benchmarks académiques (MMLU, HumanEval, GPQA) mesurent des tâches bien délimitées avec des réponses vérifiables. En production, les tâches sont souvent mal spécifiées, les données sont bruitées, et le “bon” output est ambigu. Les gains sur benchmarks ne se transfèrent pas linéairement.
Un modèle qui score 90% sur HumanEval peut produire du code fonctionnellement correct mais architecturalement problématique, ce que le benchmark ne mesure pas.
Les capacités agentiques : promesse et réalité
Claude Opus 4.5 et ses contemporains ont été présentés comme des “agents” capables d’exécuter des tâches complexes de façon autonome sur de longues chaînes d’actions. C’est vrai, avec des nuances importantes.
Ce qui marche bien : Les workflows agentiques avec un périmètre d’action bien défini, des outils clairs, et des tâches répétitives structurées. Un agent qui parcourt une liste de tickets Jira, classe chaque ticket selon un schéma prédéfini et génère un résumé, ça fonctionne de façon fiable.
Ce qui reste difficile : Les tâches longues avec des états intermédiaires ambigus, nécessitant des décisions subjectives, ou avec des boucles de feedback dépendant de contextes externes non structurés. Le taux d’erreur se cumule sur les chaînes longues. Un agent qui réussit chaque étape avec 95% de fiabilité a une fiabilité de 77% sur une chaîne de 5 étapes, et de 60% sur 10 étapes.
L’implication pour l’architecture : les systèmes agentiques en production nécessitent des points de contrôle humain bien positionnés, des mécanismes de rollback, et des limites claires sur le périmètre d’action autonome. Le “fully autonomous agent” est un objectif de lab. Le “human-in-the-loop agent avec escalade intelligente” est ce qui s’opère en production.
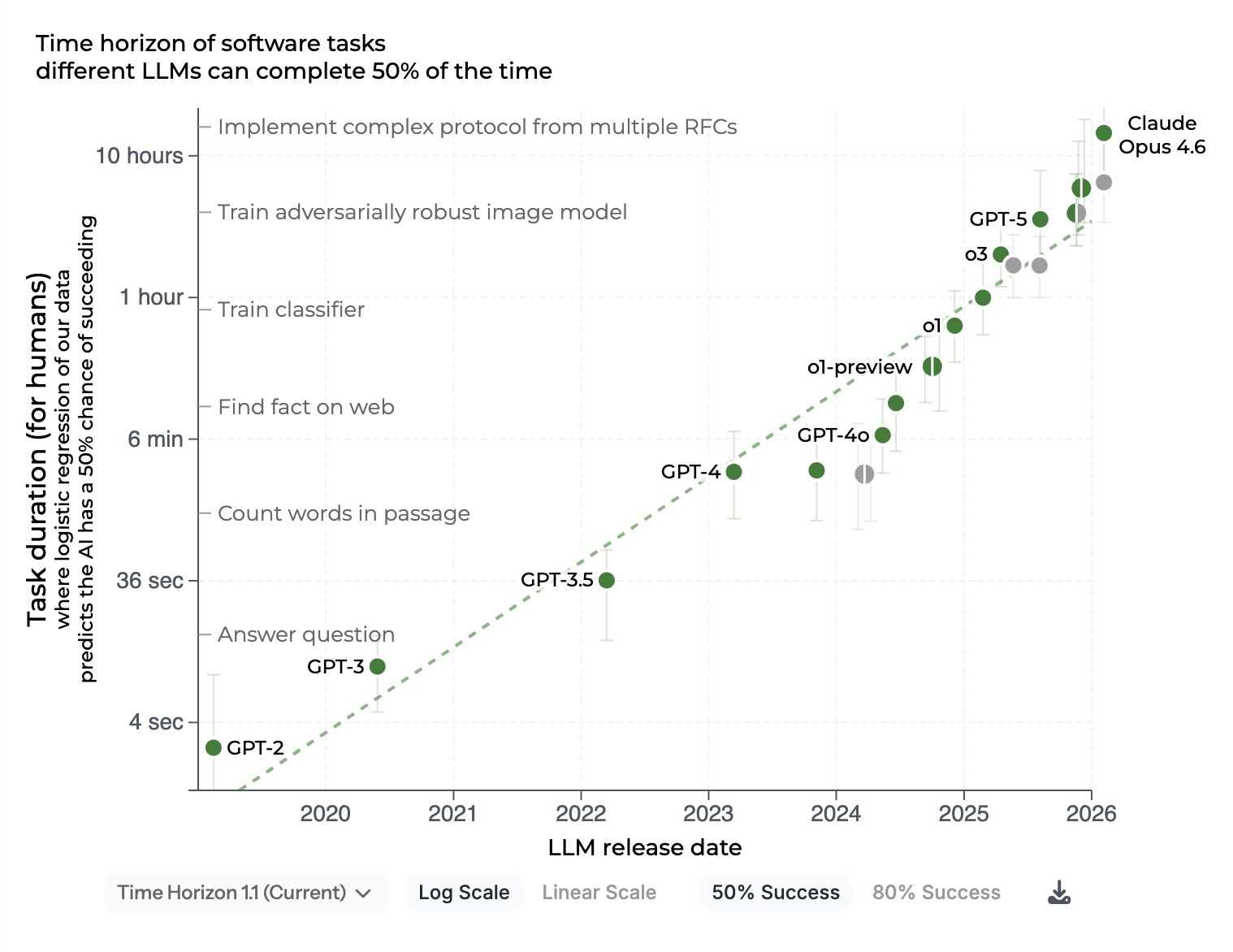
Source : METR, Measuring AI ability to complete long tasks (mis à jour février 2026). Le graphique mesure la capacité des modèles frontier à compléter de façon autonome des tâches nécessitant de 1 minute à plusieurs jours à un humain compétent. La progression entre 2019 et 2026 contextualise les enjeux de supervision et de contrôle humain.
Ce que la montée en gamme des modèles ne résout pas
Le problème de l’hallucination persiste
Les modèles frontier ont réduit leur taux d’hallucination sur les tâches bien documentées et les faits vérifiables courants. Mais l’hallucination n’a pas disparu. Elle s’est déplacée vers les cas limites, les domaines spécialisés et les questions à faible représentation dans les données d’entraînement.
Pour des systèmes en production dans des contextes critiques (analyse réglementaire, conseil médical, vérification juridique), les garde-fous restent indispensables : citations sourcées, vérification externe des affirmations factuelles, supervision humaine sur les outputs à fort impact. Un modèle plus puissant qui hallucine moins souvent mais avec plus de confiance est potentiellement plus dangereux qu’un modèle plus faible dont les limites sont connues.
La gouvernance et la traçabilité restent votre responsabilité
Un modèle plus puissant ne change pas les obligations réglementaires. L’AI Act s’applique selon l’usage du système, pas selon la sophistication du modèle. Un système de scoring crédit utilisant Claude Opus 4.5 a les mêmes obligations de traçabilité, de supervision humaine et de documentation qu’un système utilisant un modèle de génération précédente.
La tentation est de déléguer plus de décisions au modèle parce qu’il est “plus fiable”. C’est une erreur de gouvernance. La fiabilité perçue du modèle ne transfère pas la responsabilité : elle reste chez l’opérateur.
Le coût d’inférence reste une contrainte réelle
Les modèles frontier les plus puissants (Claude Opus, GPT-5, Gemini Ultra) ont des coûts d’inférence significativement plus élevés que leurs versions plus légères. Le raisonnement étendu (“extended thinking” ou “deep reasoning”) multiplie ce coût par 3 à 10.
Dans un système à fort volume (des millions de requêtes par mois), l’équation économique impose presque toujours un routing intelligent : les tâches simples vers des modèles légers et économiques, les tâches complexes vers les modèles frontier. Ce routing est lui-même un problème d’ingénierie non trivial.
Les décisions d’architecture que ça influence
Faut-il migrer vers les derniers modèles ?
La réponse n’est pas “oui, le plus récent est le meilleur”. La réponse est : évaluer sur vos propres données, vos propres tâches, vos propres critères.
Un modèle qui performe mieux sur vos evals spécifiques vaut la migration. Un modèle qui performe mieux sur les benchmarks généraux mais dont vous n’exploitez pas les capacités différenciantes ne justifie pas nécessairement le coût de migration et de re-validation.
Protocole de décision de migration :
- Définir les métriques qui comptent pour votre cas d’usage (précision, latence, coût, format de sortie)
- Constituer un dataset d’évaluation représentatif de votre production
- Tester le nouveau modèle sur ce dataset avec les mêmes prompts
- Comparer les métriques, pas les benchmarks du fournisseur
- Si les gains justifient le coût de migration, déployer en shadow mode avant bascule
Faut-il adopter les capacités agentiques ?
Seulement si le problème que vous résolvez le justifie. Les agents complexes ont un coût opérationnel élevé (débogage difficile, comportements émergents imprévus, dépendances sur des services externes). Avant d’adopter une architecture agentique, demandez-vous si un workflow déterministe avec des appels LLM ponctuels ne résout pas le problème de façon plus prévisible et plus maintenable.
Faut-il verrouiller sa dépendance sur un fournisseur ?
La diversité des modèles frontier disponibles (OpenAI, Anthropic, Google, Mistral, Meta/Llama) est une opportunité de ne pas être mono-dépendant. Les architectures qui abstraient la couche de modèle (via une gateway LLM comme LiteLLM, ou une couche d’abstraction maison) permettent de switcher de fournisseur ou de version sans refonte.
C’est particulièrement important pour les applications critiques : une dépréciation d’API, une hausse de prix, ou une dégradation de qualité ne doivent pas bloquer votre système.
La bonne posture : pragmatisme, pas hype
Les nouvelles générations de modèles ouvrent des possibilités réelles. Les ignorer serait une erreur. Les adopter sans évaluation rigoureuse en serait une autre.
La posture qui produit des résultats durables :
- Évaluer sur vos données, pas sur les benchmarks des fournisseurs
- Identifier les tâches où le gain du nouveau modèle est matériel pour votre usage
- Maintenir la gouvernance indépendamment de la puissance du modèle
- Garder des options en ne verrouillant pas l’architecture sur un fournisseur unique
- Piloter les coûts avec un routing intelligent selon la complexité des tâches
L’IA n’est pas une fin en soi. C’est un levier dont la valeur dépend de la rigueur avec laquelle vous l’intégrez dans vos systèmes et vos processus.
Vous évaluez une migration de modèle ou une nouvelle architecture IA ? Parlons de votre contexte.