“On va utiliser un modèle open source, c’est gratuit.” Cette phrase, on l’entend régulièrement en début de projet. Elle n’est pas fausse, mais elle est incomplète de façon dangereuse.
Les modèles open source (ou plus précisément : les modèles à poids ouverts) sont devenus une option sérieuse pour un grand nombre de cas d’usage. L’écart de performance avec les modèles frontier s’est réduit. Certains modèles spécialisés surpassent GPT-4 sur leurs domaines cibles. Et la souveraineté sur les données, c’est-à-dire garder les données dans votre infrastructure, est un argument réel et souvent décisif.
Mais “gratuit” signifie ici que vous ne payez pas de coût d’inférence à un fournisseur. Ça ne signifie pas qu’il n’y a pas de coût. Et “open source” cache des réalités très différentes selon les licences, les modèles et les usages.
L’écosystème en 2025-2026 : les acteurs qui comptent
Llama (Meta)
La famille Llama est devenue la référence de l’open source en termes de communauté et d’écosystème. Llama 3.3 70B est aujourd’hui compétitif avec GPT-4o sur de nombreux benchmarks de raisonnement et de génération de code. Les versions plus légères (8B) tournent sur du matériel accessible.
Le point sur la licence : la licence Llama est “community license”, pas de l’open source au sens OSI. Elle autorise l’usage commercial avec quelques restrictions (notamment une limite à 700 millions d’utilisateurs actifs mensuels, ce qui ne concerne que Meta lui-même en pratique, et des restrictions sur l’entraînement de modèles concurrents). Pour la très grande majorité des usages d’entreprise, c’est une licence permissive.
Mistral
Mistral AI est l’acteur européen de référence. Mistral Large est leur modèle frontier, mais leurs modèles open source (Mistral 7B, Mixtral 8x7B, Mistral Small) ont une excellente réputation sur les tâches de compréhension et de génération en français, ce qui est un avantage non négligeable pour des applications francophones.
Le point sur la licence : Apache 2.0 pour les modèles open source de Mistral. C’est une vraie licence open source, permissive, sans restriction commerciale. C’est l’un des acteurs les plus propres sur la dimension licences.
Qwen (Alibaba)
La famille Qwen est souvent sous-estimée en Europe. Qwen 2.5 72B rivalise avec les meilleurs modèles open source sur les tâches de raisonnement, et ses performances sur les langues asiatiques sont naturellement excellentes. Les versions quantisées tournent efficacement sur du matériel standard.
Le point sur la licence : Qianwen LICENSE Agreement, permissive pour les usages commerciaux sous 100 millions d’utilisateurs actifs mensuels.
Gemma (Google)
Gemma est la contribution de Google à l’open source. Les versions 2B et 7B sont optimisées pour tourner efficacement sur des configurations modestes (y compris CPU). Moins performants que Llama ou Qwen à paramètres équivalents, mais mieux optimisés pour les environnements contraints.
Le point sur la licence : Gemma Terms of Use, permissive pour les usages commerciaux, avec des restrictions sur l’usage pour entraîner des modèles concurrents à Google.
Phi (Microsoft)
La série Phi (Phi-3, Phi-3.5) de Microsoft est construite autour d’un objectif : maximiser les performances pour une taille de modèle minimale. Phi-3 Mini (3.8B) a des performances remarquables pour sa taille sur les tâches de raisonnement. Idéal pour les environnements edge ou les appareils à ressources limitées.
CodeLlama, DeepSeek Coder, StarCoder
Pour les usages spécifiques de génération de code, ces modèles spécialisés surpassent souvent les modèles généralistes de taille comparable. DeepSeek Coder en particulier a créé la surprise avec des performances proches de GPT-4 sur HumanEval.
”Gratuit” : le vrai calcul des coûts
L’inférence chez OpenAI ou Anthropic se paie au token. L’auto-hébergement se paie en infrastructure, en temps humain, et en maintenance. Le calcul n’est pas trivial.
Le coût du matériel
Les modèles s’exécutent sur GPU (ou CPU avec des performances dégradées). La règle empirique : il faut environ 2 Go de VRAM par milliard de paramètres pour un modèle en précision FP16. Un modèle 70B nécessite donc ~140 Go de VRAM, soit 2 à 4 GPU A100/H100, dont le coût de location cloud est de 3 à 8 €/heure par GPU.
| Modèle | VRAM requise (FP16) | Matériel indicatif |
|---|---|---|
| 7B | ~14 Go | 1× RTX 4090 ou A10 |
| 13B | ~26 Go | 1× A100 40Go |
| 34B | ~68 Go | 2× A100 40Go |
| 70B | ~140 Go | 2× A100 80Go ou 4× A100 40Go |
La quantisation change l’équation : un modèle 70B quantisé en 4 bits (GGUF Q4_K_M) tient dans ~40 Go de VRAM. Les performances se dégradent légèrement, mais sur la plupart des tâches applicatives, la différence est imperceptible.
Le coût humain
Déployer et opérer un modèle auto-hébergé requiert des compétences spécifiques :
- Configuration de l’infrastructure GPU (CUDA, drivers, containerisation)
- Déploiement du serveur d’inférence (vLLM, Ollama, Text Generation Inference, llama.cpp)
- Optimisation des performances (batching, KV cache, quantisation)
- Monitoring et maintenance (mises à jour, gestion des pannes)
Ce n’est pas insurmontable, mais c’est une compétence qui s’acquiert et se maintient. Pour une équipe qui n’a pas d’expertise MLOps, le temps de mise en place et les coûts cachés peuvent dépasser les économies réalisées sur les coûts d’inférence.
Le point d’équilibre
En règle générale, l’auto-hébergement devient économiquement intéressant à partir d’un volume d’inférence significatif, typiquement plusieurs millions de tokens par jour. En dessous, les APIs cloud sont souvent plus économiques quand on intègre tous les coûts.
Calculez votre breakeven : coût mensuel d’inférence API × 12 ÷ coût annualisé de l’infrastructure = votre point d’équilibre. Si l’infrastructure s’amortit en moins d’un an, l’auto-hébergement est probablement pertinent.
Les vrais avantages des modèles open source
Souveraineté des données
C’est l’argument le plus solide. Quand vous envoyez des données à OpenAI, Anthropic ou Google, ces données transitent par leur infrastructure. Même avec des garanties contractuelles de non-utilisation pour l’entraînement, vous perdez la maîtrise physique de vos données.
Pour des données couvertes par le secret médical, le secret des affaires, des données personnelles sensibles, ou des informations sous NDA, l’auto-hébergement n’est pas un choix d’optimisation : c’est une exigence.
Cas concrets où c’est décisif :
- Analyse de contrats confidentiels
- Traitement de données de santé (contraintes RGPD + HDS)
- Analyse de code source propriétaire
- Systèmes dans des environnements air-gapped (industrie, défense)
Personnalisation et fine-tuning
Les modèles open source peuvent être fine-tunés sur vos données propres. C’est une différenciation que les APIs cloud ne permettent pas (ou de façon très limitée et coûteuse).
Le fine-tuning a du sens quand :
- Vous avez un vocabulaire métier très spécifique non représenté dans les données d’entraînement générales
- Vous voulez un format de sortie très précis et cohérent
- Vous avez un style ou un ton particulier à maintenir
- Vous voulez améliorer les performances sur un domaine précis avec vos propres données labellisées
Attention : le fine-tuning a un coût de calcul non négligeable et requiert des données de qualité. Un fine-tuning mal exécuté dégrade les performances plutôt qu’il ne les améliore.
Prévisibilité et contrôle
Avec un modèle auto-hébergé, vous contrôlez la version exacte. Pas de mise à jour surprise du fournisseur qui change le comportement. Pas de dépréciation d’API qui force une migration urgente. Pas de hausse de prix unilatérale.
C’est particulièrement précieux pour des systèmes de production où la stabilité du comportement est critique.
Latence et intégration
Un modèle auto-hébergé dans votre infrastructure peut offrir des latences plus faibles pour des requêtes locales (pas de round-trip réseau vers une API externe). Et l’intégration dans des workflows complexes est plus flexible sans les limitations des APIs publiques (rate limits, context length, etc.).
Les limites réelles à ne pas sous-estimer
L’écart de performance sur les tâches complexes
Sur les tâches simples à moyennement complexes (extraction, classification, génération de contenu standard, code de routine), les meilleurs modèles open source sont comparables aux modèles frontier. Sur les tâches vraiment difficiles (raisonnement en plusieurs étapes sur des problèmes ambigus, compréhension fine du contexte culturel, gestion de cas limites inhabituels), l’écart reste réel avec Claude Opus ou GPT-5.
Évaluez sur vos tâches spécifiques. Ne généralisez pas à partir des benchmarks.
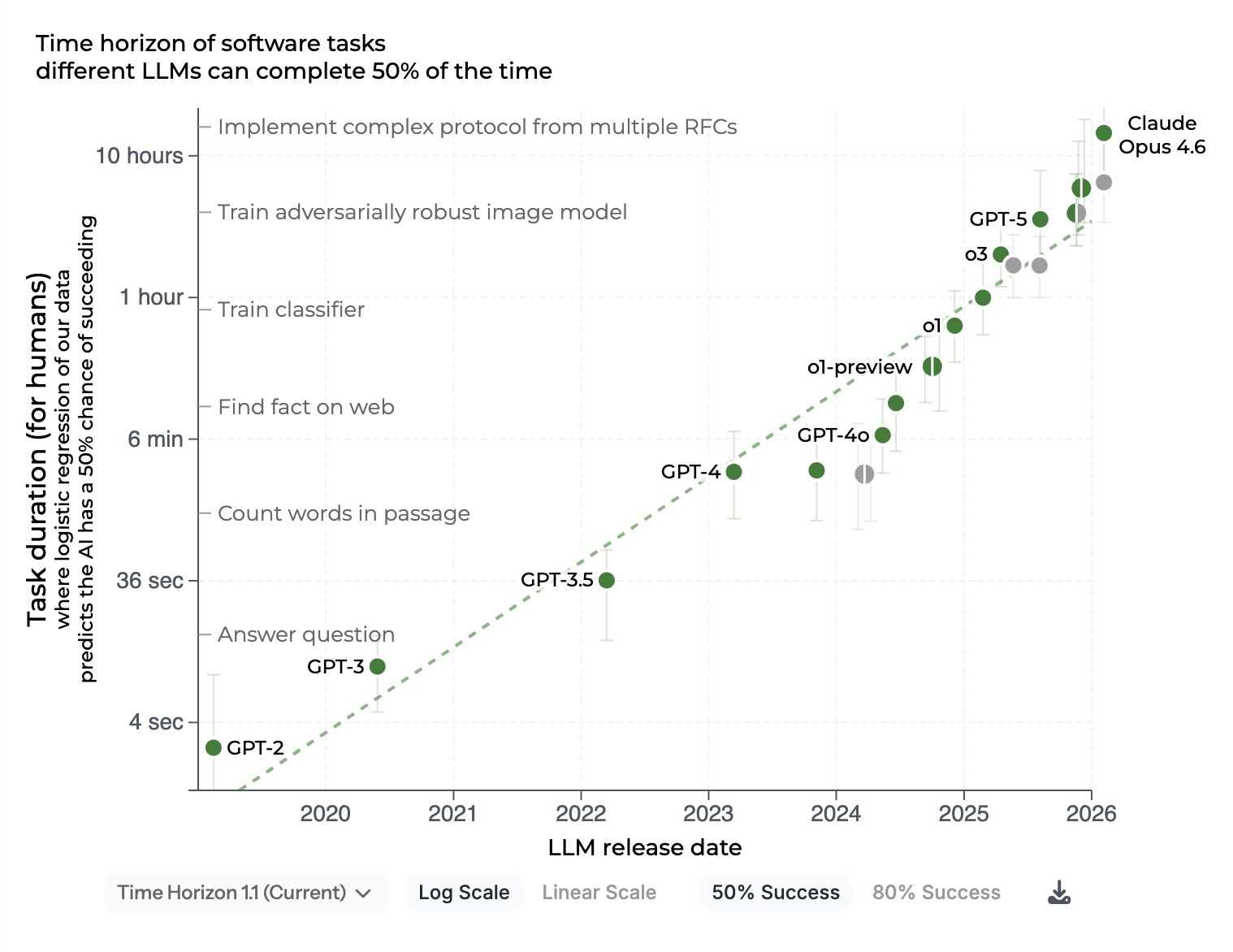
Source : METR, Measuring AI ability to complete long tasks (mis à jour février 2026). La courbe illustre la montée en capacité des modèles frontier sur les tâches longues. Les modèles open source progressent sur le même axe, mais avec un décalage visible sur les tâches les plus exigeantes.
La maintenance est votre problème
Un bug dans l’API OpenAI est réglé par OpenAI. Un bug dans votre déploiement vLLM est votre problème. Une vulnérabilité dans la stack d’inférence que vous opérez est votre responsabilité. Le support communautaire est bien, mais il ne remplace pas un contrat de support avec SLA.
Le support multimodal est moins mature
Les modèles open source multimodaux (image + texte) ont progressé, mais restent globalement en retard sur GPT-4o vision ou Gemini pour les tâches visuelles complexes. Si votre cas d’usage est vision-centrique, évaluez soigneusement avant de vous engager sur une stack open source.
Les licences : lisez-les vraiment
“Open source” ne signifie pas “faites ce que vous voulez”. Quelques points d’attention :
- Llama : interdit d’utiliser les outputs pour entraîner des modèles concurrents à Meta. Interdit de nommer un produit dérivé “Llama” sans accord.
- Certains modèles chinois : des restrictions peuvent exister sur les usages dans des contextes sensibles ou gouvernementaux selon les pays.
- Les modèles fine-tunés communautaires : héritent des licences du modèle de base. Un modèle communautaire dérivé de Llama est soumis à la licence Llama même si son auteur ne le mentionne pas.
Faites valider les licences par votre service juridique avant un déploiement commercial.
Les outils d’inférence : quel serveur choisir ?
vLLM
La référence pour la production. Optimisé pour le throughput élevé avec PagedAttention (gestion efficace du KV cache). Supporte la plupart des architectures de modèles (Llama, Mistral, Qwen, etc.). API compatible OpenAI : vous pouvez brancher vos clients OpenAI SDK sans modification.
À utiliser quand : production à volume, plusieurs requêtes concurrentes, besoin de performances maximales.
Ollama
Le choix du développeur et des déploiements mono-utilisateur. Extrêmement simple à installer et configurer. Télécharge et gère les modèles automatiquement. Quantisation intégrée. Pas optimisé pour le multi-utilisateur à volume.
À utiliser quand : développement local, prototypage, usage interne mono-utilisateur.
Text Generation Inference (TGI), Hugging Face
Bien maintenu, bonne intégration avec l’écosystème Hugging Face. Concurrent direct de vLLM, performances comparables. Supporte le streaming natif.
llama.cpp
L’option CPU. Permet de faire tourner des modèles quantisés sur CPU (sans GPU) avec des performances acceptables pour les petits modèles. Indispensable pour les environnements sans GPU ou les appareils edge.
Performances indicatives sur CPU : un modèle 7B Q4 tourne à ~5-15 tokens/seconde sur un bon CPU moderne, utilisable pour certains cas d’usage, trop lent pour d’autres.
Une approche hybride : le meilleur des deux mondes
La dichotomie “API cloud vs auto-hébergé” est souvent un faux choix. La plupart des architectures LLMOps matures combinent les deux :
- Modèles légers auto-hébergés pour les tâches à fort volume et faible complexité (classification, extraction, résumé court)
- Modèles frontier via API pour les tâches complexes ponctuelles (raisonnement multi-étapes, analyse approfondie)
- Modèle fine-tuné auto-hébergé pour les tâches métier très spécifiques où la personnalisation fait la différence
Un router LLM (LiteLLM, RouteLLM, ou maison) sélectionne le modèle adapté selon la nature de la requête. Cette architecture réduit les coûts tout en maintenant la qualité là où elle compte.

Conclusion
Les modèles open source sont une option sérieuse, pas une option par défaut. Le bon choix dépend de votre volumétrie, de vos contraintes de souveraineté, de votre capacité opérationnelle à gérer de l’infrastructure, et de la complexité réelle de vos tâches.
“Gratuit” est le mauvais critère de décision. “Adapté à mon contexte, maîtrisable dans le temps, évalué sur mes propres données”, c’est le bon.
Vous évaluez une architecture IA et le choix entre modèles cloud et auto-hébergés ? Échangeons sur votre contexte.