Every quarter brings its share of announcements: a new frontier model, record benchmarks, impressive demos. And every time, the same question from technical teams: what do we do with this?
Late 2025 was particularly dense. Anthropic’s Claude Opus 4.5, new versions of GPT-5, Gemini Ultra 2: each claims significant gains on reasoning, context window, agentic capabilities. Some of these gains are real and material for production applications. Others are improvements on academic benchmarks that do not necessarily translate into operational value.
Here is a hype-free look at what really changes.
What has actually evolved
The context window: a structural change
The context window of frontier models has crossed thresholds that change the possible architectures. Where the first GPT-4 worked on 8k tokens (approximately 6,000 words), current models operate on hundreds of thousands to several million tokens.
What this changes concretely:
The RAG pattern (Retrieval-Augmented Generation), retrieving relevant passages from a document base and injecting them into the context, remains useful for cost and precision reasons. But it is no longer the only answer to “the document is too long for the context.” Documents of several hundred pages can now be processed directly.
For document analysis systems (contracts, regulatory files, audit reports), this is a significant architectural simplification: less chunking, less retrieval logic, less risk of losing important information in the seams between fragments.
What this does not change: inference cost is proportional to tokens processed. Sending 500,000 tokens on every call for a use case that does not require it is economically absurd. RAG remains relevant for cost control on large document bases.
Reasoning: real gains on certain types of tasks
Models of the current generation (OpenAI’s “o” family, Claude with extended thinking enabled, Gemini with Deep Research) have significantly improved multi-step reasoning capabilities compared to their predecessors.
Where this is really visible:
- Analysis of multi-constraint problems (optimisation, planning)
- Complex code debugging with intermediate state tracing
- Legal or regulatory analysis requiring cross-referencing of multiple sources
- Code generation with coherent architecture on non-trivial problems
Where benchmarks overestimate the gains: Academic benchmarks (MMLU, HumanEval, GPQA) measure well-delimited tasks with verifiable answers. In production, tasks are often poorly specified, data is noisy, and the “right” output is ambiguous. Benchmark gains do not transfer linearly.
A model that scores 90% on HumanEval may produce functionally correct but architecturally problematic code, which the benchmark does not measure.
Agentic capabilities: promise and reality
Claude Opus 4.5 and its contemporaries have been presented as “agents” capable of autonomously executing complex tasks over long chains of actions. This is true, with important nuances.
What works well: Agentic workflows with a well-defined scope of action, clear tools, and structured repetitive tasks. An agent that iterates through a list of Jira tickets, classifies each ticket according to a predefined schema and generates a summary: this works reliably.
What remains difficult: Long tasks with ambiguous intermediate states, requiring subjective decisions, or with feedback loops depending on unstructured external contexts. Error rates accumulate over long chains. An agent that succeeds at each step with 95% reliability has 77% reliability over a 5-step chain, and 60% over 10 steps.
The implication for architecture: agentic systems in production require well-positioned human control points, rollback mechanisms, and clear limits on the scope of autonomous action. The “fully autonomous agent” is a lab objective. The “human-in-the-loop agent with intelligent escalation” is what operates in production.
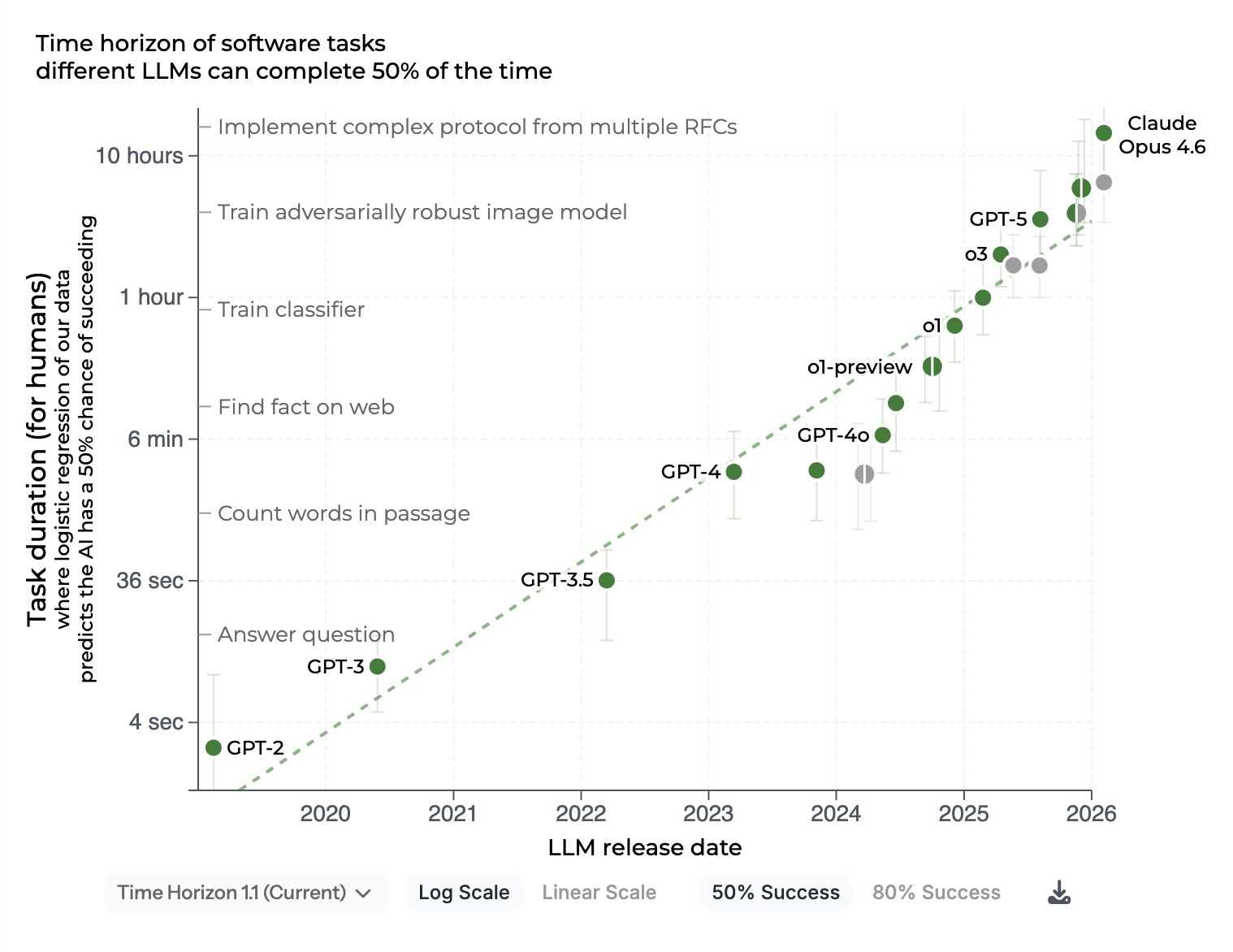
Source: METR, Measuring AI ability to complete long tasks (updated February 2026). The chart tracks frontier models’ ability to autonomously complete tasks requiring 1 minute to several days for a skilled human. The progression from 2019 to 2026 contextualises the stakes around human oversight and control.
What the upgrade of models does not solve
The hallucination problem persists
Frontier models have reduced their hallucination rate on well-documented tasks and common verifiable facts. But hallucination has not disappeared. It has shifted to edge cases, specialised domains and questions with low representation in training data.
For production systems in critical contexts (regulatory analysis, medical advice, legal verification), guardrails remain indispensable: sourced citations, external verification of factual claims, human oversight on high-impact outputs. A more powerful model that hallucinates less often but with more confidence is potentially more dangerous than a weaker model whose limits are known.
Governance and traceability remain your responsibility
A more powerful model does not change regulatory obligations. The AI Act applies based on the use of the system, not the sophistication of the model. A credit scoring system using Claude Opus 4.5 has the same traceability, human oversight and documentation obligations as a system using a previous generation model.
The temptation is to delegate more decisions to the model because it is “more reliable.” This is a governance error. The perceived reliability of the model does not transfer responsibility. It remains with the operator.
Inference cost remains a real constraint
The most powerful frontier models (Claude Opus, GPT-5, Gemini Ultra) have significantly higher inference costs than their lighter versions. Extended reasoning (“extended thinking” or “deep reasoning”) multiplies this cost by 3 to 10.
In a high-volume system (millions of requests per month), the economic equation almost always requires intelligent routing: simple tasks to lightweight, economical models; complex tasks to frontier models. This routing is itself a non-trivial engineering problem.
The architecture decisions this influences
Should you migrate to the latest models?
The answer is not “yes, the most recent is the best.” The answer is: evaluate on your own data, your own tasks, your own criteria.
A model that performs better on your specific evals is worth migrating to. A model that performs better on general benchmarks but whose differentiating capabilities you do not exploit does not necessarily justify the cost of migration and re-validation.
Migration decision protocol:
- Define the metrics that matter for your use case (accuracy, latency, cost, output format)
- Build an evaluation dataset representative of your production
- Test the new model on this dataset with the same prompts
- Compare the metrics, not the provider’s benchmarks
- If the gains justify the migration cost, deploy in shadow mode before switching
Should you adopt agentic capabilities?
Only if the problem you are solving justifies it. Complex agents have a high operational cost (difficult debugging, unexpected emergent behaviours, dependencies on external services). Before adopting an agentic architecture, ask yourself whether a deterministic workflow with punctual LLM calls does not solve the problem in a more predictable and maintainable way.
Should you lock in your dependency on a provider?
The diversity of frontier models available (OpenAI, Anthropic, Google, Mistral, Meta/Llama) is an opportunity not to be mono-dependent. Architectures that abstract the model layer (via an LLM gateway like LiteLLM, or an in-house abstraction layer) allow switching provider or version without redesign.
This is particularly important for critical applications: an API deprecation, a price increase, or a quality degradation must not block your system.
The right posture: pragmatism, not hype
New generations of models open up real possibilities. Ignoring them would be a mistake. Adopting them without rigorous evaluation would be another.
The posture that produces lasting results:
- Evaluate on your data, not on provider benchmarks
- Identify the tasks where the new model’s gain is material for your use
- Maintain governance independently of the model’s power
- Keep options open by not locking the architecture to a single provider
- Control costs with intelligent routing based on task complexity
AI is not an end in itself. It is a lever whose value depends on the rigour with which you integrate it into your systems and processes.
Are you evaluating a model migration or a new AI architecture? Let’s talk about your context.