“We’ll use an open source model, it’s free.” This phrase is heard regularly at the start of projects. It is not wrong, but it is dangerously incomplete.
Open source models (or more precisely: open-weight models) have become a serious option for a large number of use cases. The performance gap with frontier models has narrowed. Some specialised models outperform GPT-4 on their target domains. And data sovereignty, keeping data within your infrastructure, is a real and often decisive argument.
But “free” here means you do not pay inference costs to a provider. It does not mean there is no cost. And “open source” conceals very different realities depending on the licences, models and uses.
The 2025-2026 ecosystem: the players that matter
Llama (Meta)
The Llama family has become the reference for open source in terms of community and ecosystem. Llama 3.3 70B is now competitive with GPT-4o on many reasoning and code generation benchmarks. Lighter versions (8B) run on accessible hardware.
On the licence: the Llama licence is a “community licence”, not open source in the OSI sense. It permits commercial use with some restrictions (notably a limit of 700 million monthly active users, which in practice only concerns Meta itself, and restrictions on training competing models). For the vast majority of enterprise uses, it is a permissive licence.
Mistral
Mistral AI is the European reference player. Mistral Large is their frontier model, but their open source models (Mistral 7B, Mixtral 8x7B, Mistral Small) have an excellent reputation for comprehension and generation tasks in French, a non-trivial advantage for French-language applications.
On the licence: Apache 2.0 for Mistral’s open source models. This is a true open source licence, permissive, with no commercial restrictions. It is one of the cleanest players on the licence dimension.
Qwen (Alibaba)
The Qwen family is often underestimated in Europe. Qwen 2.5 72B rivals the best open source models on reasoning tasks, and its performance on Asian languages is naturally excellent. Quantised versions run efficiently on standard hardware.
On the licence: Qianwen Licence Agreement, permissive for commercial uses under 100 million monthly active users.
Gemma (Google)
Gemma is Google’s contribution to open source. The 2B and 7B versions are optimised to run efficiently on modest configurations (including CPU). Less performant than Llama or Qwen at equivalent parameters, but better optimised for constrained environments.
On the licence: Gemma Terms of Use, permissive for commercial uses, with restrictions on use for training models competing with Google.
Phi (Microsoft)
Microsoft’s Phi series (Phi-3, Phi-3.5) is built around one objective: maximising performance for minimum model size. Phi-3 Mini (3.8B) has remarkable performance for its size on reasoning tasks. Ideal for edge environments or resource-constrained devices.
CodeLlama, DeepSeek Coder, StarCoder
For specific code generation uses, these specialised models often outperform generalist models of comparable size. DeepSeek Coder in particular caused a surprise with GPT-4-level performance on HumanEval.
”Free”: the real cost calculation
Inference with OpenAI or Anthropic is paid per token. Self-hosting is paid in infrastructure, human time, and maintenance. The calculation is not trivial.
The hardware cost
Models run on GPU (or CPU with degraded performance). The rule of thumb: approximately 2 GB of VRAM per billion parameters for a model in FP16 precision. A 70B model therefore requires ~140 GB of VRAM, meaning 2 to 4 A100/H100 GPUs, whose cloud rental cost is 3 to 8 €/hour per GPU.
| Model | Required VRAM (FP16) | Indicative hardware |
|---|---|---|
| 7B | ~14 GB | 1× RTX 4090 or A10 |
| 13B | ~26 GB | 1× A100 40GB |
| 34B | ~68 GB | 2× A100 40GB |
| 70B | ~140 GB | 2× A100 80GB or 4× A100 40GB |
Quantisation changes the equation: a 70B model quantised to 4 bits (GGUF Q4_K_M) fits in ~40 GB of VRAM. Performance degrades slightly, but on most application tasks the difference is imperceptible.
The human cost
Deploying and operating a self-hosted model requires specific skills:
- GPU infrastructure configuration (CUDA, drivers, containerisation)
- Inference server deployment (vLLM, Ollama, Text Generation Inference, llama.cpp)
- Performance optimisation (batching, KV cache, quantisation)
- Monitoring and maintenance (updates, fault management)
This is not insurmountable, but it is a skill that is acquired and maintained. For a team without MLOps expertise, the setup time and hidden costs can exceed the savings made on inference costs.
The break-even point
As a general rule, self-hosting becomes economically interesting from a significant inference volume, typically several million tokens per day. Below this, cloud APIs are often more economical when all costs are factored in.
Calculate your break-even: monthly API inference cost × 12 ÷ annualised infrastructure cost = your break-even point. If the infrastructure pays for itself in less than a year, self-hosting is probably relevant.
The real advantages of open source models
Data sovereignty
This is the strongest argument. When you send data to OpenAI, Anthropic or Google, that data transits through their infrastructure. Even with contractual guarantees of non-use for training, you lose physical control of your data.
For data covered by medical confidentiality, trade secrets, sensitive personal data, or information under NDA, self-hosting is not an optimisation choice. It is a requirement.
Concrete cases where this is decisive:
- Analysis of confidential contracts
- Health data processing (GDPR + health data hosting constraints)
- Proprietary source code analysis
- Systems in air-gapped environments (industry, defence)
Customisation and fine-tuning
Open source models can be fine-tuned on your own data. This is a differentiation that cloud APIs do not allow (or only in very limited and expensive ways).
Fine-tuning makes sense when:
- You have highly specific business vocabulary not represented in general training data
- You want a very precise and consistent output format
- You have a particular style or tone to maintain
- You want to improve performance on a specific domain with your own labelled data
Note: fine-tuning has a non-negligible compute cost and requires quality data. A poorly executed fine-tuning degrades performance rather than improving it.
Predictability and control
With a self-hosted model, you control the exact version. No surprise provider updates that change behaviour. No API deprecation forcing an urgent migration. No unilateral price increases.
This is particularly valuable for production systems where behavioural stability is critical.
Latency and integration
A self-hosted model within your infrastructure can offer lower latencies for local requests (no network round-trip to an external API). And integration into complex workflows is more flexible without the limitations of public APIs (rate limits, context length, etc.).
Real limitations not to underestimate
The performance gap on complex tasks
On simple to moderately complex tasks (extraction, classification, standard content generation, routine code), the best open source models are comparable to frontier models. On truly difficult tasks (multi-step reasoning on ambiguous problems, nuanced cultural context understanding, handling unusual edge cases), the gap with Claude Opus or GPT-5 remains real.
Evaluate on your specific tasks. Do not generalise from benchmarks.
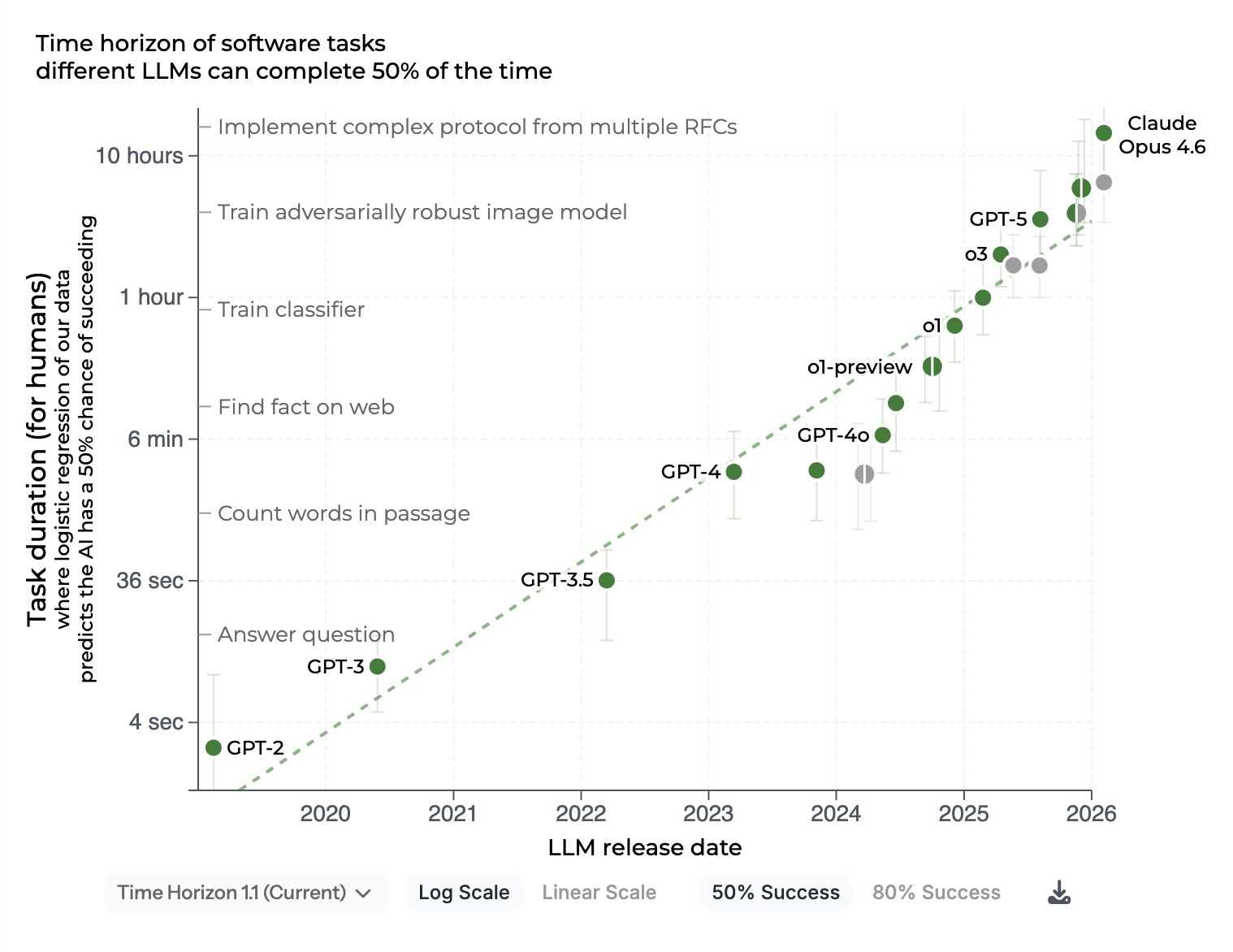
Source: METR, Measuring AI ability to complete long tasks (updated February 2026). The curve illustrates how frontier models have improved on long-horizon tasks. Open source models follow the same trajectory, but with a visible lag on the most demanding tasks.
Maintenance is your problem
A bug in the OpenAI API is fixed by OpenAI. A bug in your vLLM deployment is your problem. A vulnerability in the inference stack you operate is your responsibility. Community support is good, but it does not replace a support contract with SLAs.
Multimodal support is less mature
Open source multimodal models (image + text) have progressed, but remain generally behind GPT-4o vision or Gemini for complex visual tasks. If your use case is vision-centric, evaluate carefully before committing to an open source stack.
Licences: actually read them
“Open source” does not mean “do what you like.” A few points to watch:
- Llama: prohibited from using outputs to train models competing with Meta. Prohibited from naming a derivative product “Llama” without agreement.
- Some Chinese models: restrictions may exist on uses in sensitive or governmental contexts depending on the country.
- Community fine-tuned models: inherit the licences of the base model. A community model derived from Llama is subject to the Llama licence even if its author does not mention it.
Have licences validated by your legal team before a commercial deployment.
Inference tools: which server to choose?
vLLM
The reference for production. Optimised for high throughput with PagedAttention (efficient KV cache management). Supports most model architectures (Llama, Mistral, Qwen, etc.). OpenAI-compatible API, so you can plug in your OpenAI SDK clients without modification.
Use when: production at scale, multiple concurrent requests, need for maximum performance.
Ollama
The developer’s choice and for single-user deployments. Extremely simple to install and configure. Downloads and manages models automatically. Built-in quantisation. Not optimised for high-volume multi-user.
Use when: local development, prototyping, single-user internal use.
Text Generation Inference (TGI), Hugging Face
Well maintained, good integration with the Hugging Face ecosystem. Direct competitor to vLLM, comparable performance. Supports native streaming.
llama.cpp
The CPU option. Allows running quantised models on CPU (without GPU) with acceptable performance for small models. Essential for environments without GPU or edge devices.
Indicative CPU performance: a 7B Q4 model runs at ~5-15 tokens/second on a good modern CPU, usable for some use cases, too slow for others.
A hybrid approach: the best of both worlds
The “cloud API vs self-hosted” dichotomy is often a false choice. Most mature LLMOps architectures combine both:
- Self-hosted lightweight models for high-volume, low-complexity tasks (classification, extraction, short summaries)
- Frontier models via API for occasional complex tasks (multi-step reasoning, in-depth analysis)
- Self-hosted fine-tuned model for highly specific business tasks where customisation makes the difference
An LLM router (LiteLLM, RouteLLM, or in-house) selects the appropriate model based on the nature of the request. This architecture reduces costs while maintaining quality where it matters.

Conclusion
Open source models are a serious option, not a default option. The right choice depends on your volume, your sovereignty constraints, your operational capacity to manage infrastructure, and the real complexity of your tasks.
“Free” is the wrong decision criterion. “Adapted to my context, manageable over time, evaluated on my own data”: that is the right one.
Are you evaluating an AI architecture and the choice between cloud and self-hosted models? Let’s discuss your context.